https://rosalind.info/problems/lrep/
ROSALIND | Finding the Longest Multiple Repeat
It appears that your browser has JavaScript disabled. Rosalind requires your browser to be JavaScript enabled. Finding the Longest Multiple Repeat solved by 609 2012년 8월 23일 12:00:00 오전 by btjaden Topics: Graph Algorithms Long Repeats We saw in
rosalind.info
A repeated substring of a string ss of length nn is simply a substring that appears in more than one location of ss; more specifically, a k-fold substring appears in at least k distinct locations.
The suffix tree of ss, denoted T(s)T(s), is defined as follows:
- T(s)T(s) is a rooted tree having exactly nn leaves.
- Every edge of T(s)T(s) is labeled with a substring of s∗s∗, where s∗s∗ is the string formed by adding a placeholder symbol $ to the end of ss.
- Every internal node of T(s)T(s) other than the root has at least two children; i.e., it has degree at least 3.
- The substring labels for the edges leading from a node to its children must begin with different symbols.
- By concatenating the substrings along edges, each path from the root to a leaf corresponds to a unique suffix of s∗s∗.
See Figure 1 for an example of a suffix tree.
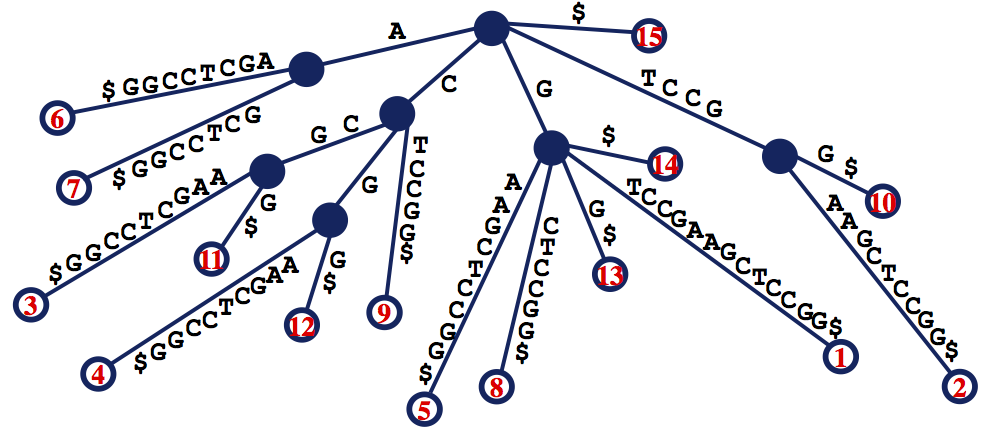{kind=link}
Given: A DNA string ss (of length at most 20 kbp) with $ appended, a positive integer kk, and a list of edges defining the suffix tree of ss. Each edge is represented by four components:
- the label of its parent node in T(s)T(s);
- the label of its child node in T(s)T(s);
- the location of the substring tt of s∗s∗ assigned to the edge; and
- the length of tt.
Return: The longest substring of ss that occurs at least kk times in ss. (If multiple solutions exist, you may return any single solution.)
Sample Dataset
CATACATAC$
2
node1 node2 1 1
node1 node7 2 1
node1 node14 3 3
node1 node17 10 1
node2 node3 2 4
node2 node6 10 1
node3 node4 6 5
node3 node5 10 1
node7 node8 3 3
node7 node11 5 1
node8 node9 6 5
node8 node10 10 1
node11 node12 6 5
node11 node13 10 1
node14 node15 6 5
node14 node16 10 1
Sample Output
CATAC
이 문제는 서열s, 정수 k, 그리고 parent node, child node, substring의 location과 길이가 주어지고, 가장 긴 repeated substring을 구하는 문제이다.
먼저 repeated substring이란 2개의 location에서 나타나는 substring을 이야기한다. 예시의 CATACATAC에서 TAC는 3,7번 자리에서 2번 나타났다.
그리고 T(s) suffix tree는 연결된 edge들을 따라가다보면 그 문자열의 모든 suffix를 찾을 수 있게되는 트리이다. 이러한 suffix tree에서 repeated substring은 node1에서 시작하여 edge에 연결된 node가 여러 개의 edge를 가질때 그 위의 edge를 반복되었다고 생각할 수 있다. 이는 예시를 그림으로 나타낸 후에 설명하겠다.

이 사진을 보면 node1에서 시작을 하여 C를 타고 node2로 향하는 것을 볼 수 있다. 이때, C가 node2를 향하고 node2는 $인 엣지에 달려있는 leaf node가 3개 있으므로 3번 중복된다고 추정할 수 있다. 이는 실제 서열에서도 똑같다. 같은 예시로 node1 - C -node2 - ATAC - node3으로 이어지는 것을 보면 node3 아래로는 2개의 laef node가 있는 것을 볼 수 있다. 그러므로 CATAC는 2번 중복된다고 생각할 수 있고 이는 실제로도 그렇다. 일종의 node가 2개 이상의 edge를 갖고 있다면 그 전까지의 서열이 다른 자리에 동시에 존재해있다고도 생각할 수 있는 것이다.
이러한 원리를 이용하여 node 아래의 leaf node 개수 세기만을 한다면, 쉽게 몇번 중복되는지 구할 수 있고, DFS나 BFS로 그래프를 타서 모든 서열에 대해서 구할 수 있다.
from collections import defaultdict
from collections import deque
node_edge_node = defaultdict(dict)
def finding_leaf(node):
que=deque()
que.append(node)
leaf=0
while que:
now_node = que.popleft()
for edge in node_edge_node[now_node].keys():
if edge[-1] == '$':
leaf+=1
else:
que.append(node_edge_node[now_node][edge])
return leaf
def making_repeat(now_node,now_seq):
if now_node not in internodes:
return
if finding_leaf(now_node) >= at_least:
anss.append(now_seq)
edges = node_edge_node[now_node].keys()
for edge in edges:
new_seq = now_seq + edge
making_repeat(node_edge_node[now_node][edge],new_seq)
if __name__ == '__main__':
with open(r"파일경로",'r') as f:
sequence = next(f).rstrip()
at_least = int(next(f).rstrip())
for i in f.readlines():
parent_node ,child_node, location, length = (i.rstrip()).split()
location= int(location)
length = int(length)
edge = sequence[location-1:location-1+length]
node_edge_node[parent_node][edge] = child_node
internodes = node_edge_node.keys()
anss=[]
making_repeat('node1','')
anss.sort(key=len,reverse=True)
with open(r"파일경로",'w') as wf:
print(anss[0],file=wf)이번 코드는 변수명도 친절히 써놨기에, 주석은 귀찮으니 달지 않겠다
'문제해결(PS) > ROSALIND' 카테고리의 다른 글
| Wobble Bonding and RNA Secondary Structures (0) | 2024.11.09 |
|---|---|
| Newick Format with Edge Weights (1) | 2024.11.09 |
| Finding Disjoint Motifs in a Gene (2) | 2024.11.03 |
| Independent Segregation of Chromosomes (1) | 2024.11.02 |
| Inferring Peptide from Full Spectrum (0) | 2024.11.02 |